圖片連結:https://finance.ettoday.net/news/2508595
為什麼需要情感辨識?
人類天生會看臉、聽聲音來理解情緒,但 AI 光靠單一訊號常常不準。
業界觀點:Nvidia CEO的提醒
Nvidia 執行長 黃仁勳 (Jensen Huang) 曾經說過:
“There’s a lot of information in life that has to be grounded by video, grounded by physics. So that’s the next big thing.”
這句話強調未來 AI 模型不僅要處理文字或語音,更要「根植於影像與物理感測」。
換句話說,多模態融合(特別是影像、聲音、物理感測數據的結合)將會是 AI 的「下一個大浪潮」。
「從情感辨識到遙感影像,從市場數據到產業觀點,多模態 AI 正在成為人類智慧的延伸。未來 AI 不只是學會看或聽,而是要真正理解世界。」
智慧不只是知識,而是同理心、判斷力與跨模態的整合理解 ; 而情感辨識,就是 AI 嘗試學習這種「智慧」的一個縮影。
這些資料集是做情感辨識的基石,提供標註好的「臉/聲音 → 情緒」數據。
RAVDESS
介紹:情感語音歌曲的數據集,由24 位演員(男女各 半),錄製(語音 + 歌唱)的情緒表達。
標註情緒:happy, sad, angry, fearful, calm, surprise, disgust, neutral。
特點:多模態(聲音 + 視覺),適合做 Audio + Video 的情感辨識。
FER2013
出自 Kaggle 比賽,只有靜態人臉圖片。
含 35,887 張灰階 48×48 圖片。
標註情緒:7 種(憤怒angry, 厭惡disgust, 恐懼fear, 快樂happy, 悲傷sad, 驚訝surprise, 中性neutral)
特點:簡單好用,常作為 CNN 表情辨識入門 dataset。
AffectNet
全球最大的人臉表情資料庫之一。
440,000 張有情緒標籤的臉部圖片。
標註方式:透過網路爬蟲蒐集、人工標記。
特點:規模大、涵蓋更廣的情緒光譜,適合做深度學習研究。
import torch
import torch.nn as nn
class VisionEncoder(nn.Module):
def __init__(self, in_dim=512, hidden=256, num_classes=7):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(in_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, num_classes)
)
def forward(self, x):
return self.mlp(x)
class AudioEncoder(nn.Module):
def __init__(self, in_dim=128, hidden=128, num_classes=7):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(in_dim, hidden),
nn.ReLU(),
nn.Linear(hidden, num_classes)
)
def forward(self, x):
return self.mlp(x)
class LateFusion(nn.Module):
def __init__(self, num_classes=7):
super().__init__()
self.vision = VisionEncoder()
self.audio = AudioEncoder()
self.fusion_head = nn.Linear(num_classes*2, num_classes)
def forward(self, vision_feats, audio_feats):
logits_v = self.vision(vision_feats)
logits_a = self.audio(audio_feats)
fused = torch.cat([logits_v, logits_a], dim=-1)
return self.fusion_head(fused)
vision_feats = torch.randn(4, 512)
audio_feats = torch.randn(4, 128)
model = LateFusion(num_classes=7)
output = model(vision_feats, audio_feats)
print(output.shape) # torch.Size([4, 7])
除了情感辨識,Multimodal AI 在更多領域也展現價值。
AI能快速從 RAVDESS、FER2013、AffectNet 學會「特徵對應情緒」
實務案例:遙感影像 + 多光譜/LiDAR
在 《General-Purpose Multimodal Transformer meets Remote Sensing Semantic Segmentation》 這篇研究中,研究者將 衛星多光譜 / 高光譜圖像 與 LiDAR DSM 結合,應用於地物語義分割 (semantic segmentation)。
這樣的多模態融合,不僅能處理複雜場景,還能解決「物件尺度差異」與「類別不平衡」這些難題,展現了多模態AI在地理空間應用的威力。下圖為多模態應用示意。
說明:多模態不只是學術名詞,而是真的在影像處理與感測領域帶來突破。
論文連結https://arxiv.org/abs/2307.03388?utm_source=chatgpt.com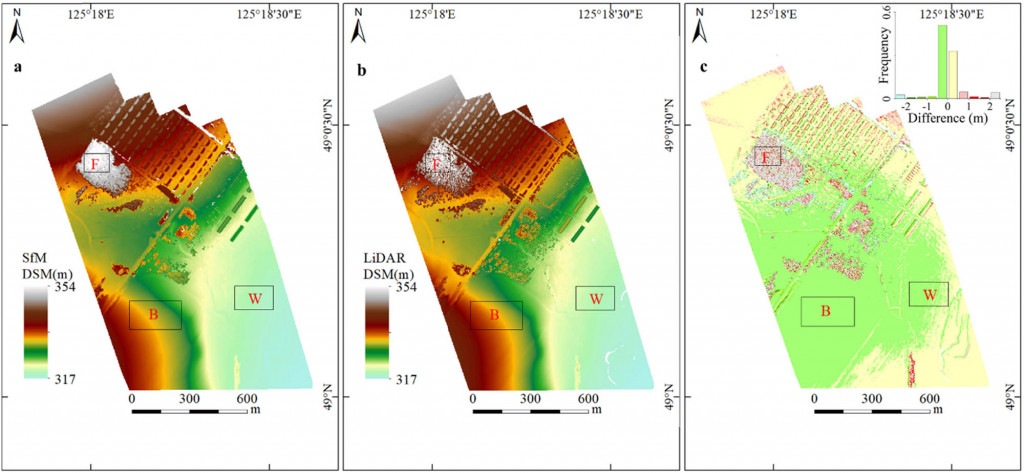
圖片連結:https://www.degruyterbrill.com/document/doi/10.1515/geo-2020-0257/html?lang=en
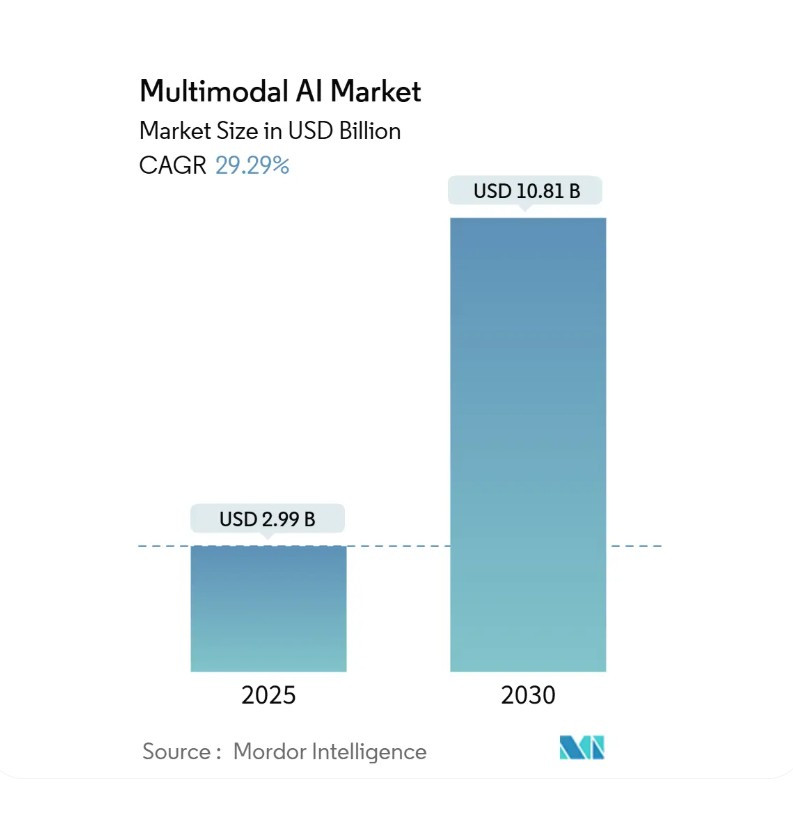
市場數據:多模態 AI 成長潛力
根據 Mordor Intelligence 報告,全球多模態 AI 市場在 2025 年規模約 29.9 億美元,並預計在 2030 年成長至 108.1 億美元,年均複合成長率 (CAGR) 約 29.29%。
北美仍是主要市場,但 亞太地區成長最快。特別是在 醫療保健 (Healthcare) 與 零售/電商 (Retail & E-commerce) 等領域,已經開始大規模落地應用。下圖為市場數據趨勢。
Mordor Intelligence 報告https://www.mordorintelligence.com/industry-reports/multimodal-ai-market?utm_source=chatgpt.com
 abc11032203
abc11032203